Observe and intervene
v1Watch a live agent run and step in before interface drift, bad reasoning, or unsafe edits become final.
- Maps
- Axes 01, 10, 12
- Carrier
- Instrumented coding runs with planted drift, conflict, or harmful-edit checkpoints.
Meta-Agent Bench evaluates whether a meta-agent improves an agentic workflow over the same workers with meta-actions disabled. CooperBench (paired feature-fix tasks for two workers in shared sandboxes) is the N=2 anchor; the first real slice pushes to N=3 and N=5 coding coordination.
The benchmark has three jobs: identify the core meta-agent functions, compare models and scaffolds on those functions, and show where first-class meta-actions like checkpoint and revert create real leverage.
Meta-Agent Bench should not just be a demo page for one framework. It should define the core functions of a meta-agent, compare different model/scaffold choices under a same-system counterfactual, and make framework-specific advantages measurable rather than assumed.
The directions should name what meta-agents uniquely do: observe, branch, revert, decompose, distill workflows, optimize scaffolds, allocate resources, and prevent unsafe actions.
Run the same tasks with general coding-agent scaffolds, custom workers, and our framework. The comparison is always against the same setup with the target meta-action disabled.
Other systems may approximate reversion by manual undo. A first-class checkpoint/revert action should show up as higher recovery, lower cost, and fewer failed continuations.
The 18-axis taxonomy was useful for exploration, but it is too fine-grained for a benchmark reader. The v1 framing should be 8 directions: each names a meta-agent capability in plain language, maps back to the technical axes, and can host one or more concrete task carriers.
Watch a live agent run and step in before interface drift, bad reasoning, or unsafe edits become final.
Fork at uncertain decisions, explore multiple continuations from the same prefix, and select the branch most likely to solve.
Detect harmful or bad actions, localize their cause, choose the right rollback granularity, and continue productively.
Turn a large task into dependent subtasks, assign workers, manage dependencies, and integrate outputs.
Turn messy completed traces into reusable workflows, checklists, scripts, or policies that transfer to related tasks.
Use evaluator feedback to improve prompts, scaffolds, tool policies, code, or meta-policies under a fixed budget.
Decide when to spend budget, invoke a stronger verifier, grant broader tool scope, or keep the cheap path.
Prevent prompt injection, hostile tool outputs, unsafe subagent behavior, and untrusted content from corrupting the workflow.
Start by making each v1 direction concrete enough to choose task settings. Decompose and orchestrate can still use CooperBench as the N=2 anchor, but the full v1 settings pass now covers the resource and safety control surfaces too.
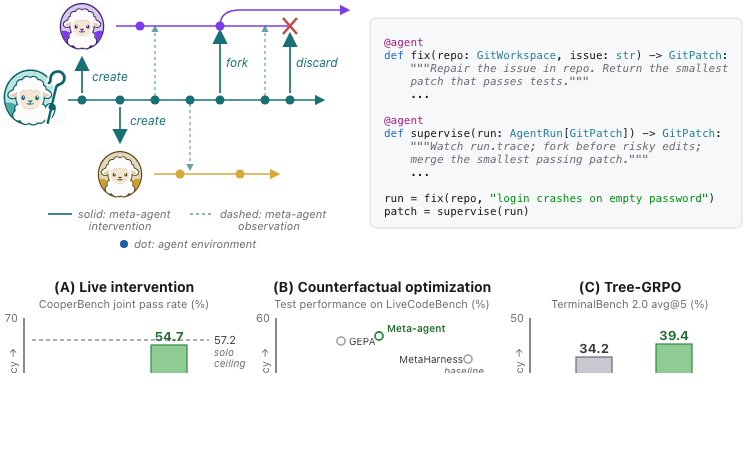
@agent API hook (top right); and three empirical anchors (live intervention, counterfactual optimization, Tree-GRPO). Solid teal = meta-agent action; dashed = observation. | order | slice | task carrier | primary metric | diagnostic |
|---|---|---|---|---|
| 01 | Observe and intervene | Live coding runs with planted drift, conflict, or harmful-edit checkpoints | Intervention Success Rate | Intervention Gain |
| 02 | Revert and recover | Bad-worker or harmful-edit variants inside coding bundles | Safe Recovery Rate | False Recovery Cost |
| 03 | Branch and select | TB2 fork-and-pick tasks at fixed budget | Task Pass Rate | Branching Gain |
| 04 | Decompose and orchestrate | CooperBench N=2 anchor; mined N=3 main set; curated N=5 stress set | Joint Pass Rate | Orchestration Gain |
| 05 | Distill and reuse | TB2/SWE completed traces converted into reusable procedures | Transfer Pass Rate | Trace-to-Workflow Gain |
| 06 | Optimize and adapt | HoVer/IFBench held-out optimization; AlphaEvolve-style evaluator loops later | Held-Out Score | Optimization Gain |
| 07 | Allocate and prioritize | Budget sweeps, model escalation, verifier routing, least-privilege tool grants | Budgeted Pass Rate | Allocation Gain |
| 08 | Prevent and contain | Injection, hostile tool output, and harmful-edit prevention tasks | Safe Completion Rate | False Block Rate |
Each v1 direction should correspond to a visible control pattern in the run log. The diagrams show the run pattern; the rows below name the operations the harness must expose.
Live control over an ongoing run before the bad state becomes the final answer.
observe(run)Read trace events, tool calls, diffs, tests, and worker messages. flag(event)Mark drift, conflict, unsafe edit, or low-confidence decision points. interrupt(run)Pause the worker before the risky action becomes final. steer(run,msg)Inject a correction, constraint, or verification request and resume. Choose the right rollback point and resume without losing useful work.
checkpoint()Save environment, repo, tool state, and trace prefix at safe boundaries. localize()Identify which action or span introduced the bad state. revert(id)Roll back to a checkpoint or action-level state, then continue. verify()Run tests or guards to confirm recovery without false rollback cost. Spend parallel budget from one shared prefix, then select a continuation.
fork(k)Create K continuations from the same trace, repo, and model prefix. rollout()Run branches independently under the same budget contract. score(branch)Use tests, verifier output, or reward to compare candidates. select(id)Commit the best branch and discard losing continuations. Make parallel work real: split dependencies, assign workers, and integrate one coherent output.
decompose()Split one large task into dependency-aware worker assignments. spawn(role)Create workers with scoped context, tools, and deliverables. sync(deps)Track blockers, shared interfaces, and cross-worker assumptions. integrate()Reconcile outputs into one patch/artifact and run joint verification. Convert one messy successful run into a reusable procedure that helps related tasks.
parse(trace)Segment a completed run into decisions, checks, failures, and fixes. distill()Extract a reusable checklist, script, prompt, or scaffold policy. replay(flow)Apply the distilled workflow on related tasks with fresh workers. measure()Score transfer against raw traces or random compression baselines. Improve the scaffold itself through evaluator feedback, while holding out tasks for scoring.
propose()Generate prompt, policy, tool, code, or scaffold variants. evaluate()Run variants on training tasks with a fixed scorer and budget. select()Keep the best variant or ensemble under the optimization objective. holdout()Report final gain only on tasks not used during optimization. Spend extra budget only when it changes the outcome, not as a default tax on every task.
budget(task)Set token, time, branch, or worker budget from task state and uncertainty. route(model)Choose cheap worker, stronger model, verifier, or specialist at decision points. scope(tools)Grant the minimum tool access needed for the current subtask. escalate()Spend extra verification or model budget only when risk justifies it. Stop unsafe or adversarial content before it reaches the worker's executable context.
screen(input)Classify external content, tool output, and subagent messages as trusted or untrusted. sandbox(tool)Run risky tools or workers in an isolated scope before granting broader access. block(action)Prevent unsafe instructions, exfiltration, or destructive edits before execution. sanitize(ctx)Strip or quote untrusted instructions before passing context to workers. CL-Bench's cleanest move is the same-system counterfactual. We keep that structure, but replace "stateful vs stateless" with "meta-actions enabled vs disabled." Meta Gain is the one cross-direction headline number.
Each direction reports two numbers: a task-natural primary (e.g. Joint Pass Rate, Safe Recovery Rate, Held-Out Score) that lets readers compare absolute capability, and a Meta Gain entry that isolates what the meta-actions added on top. The leaderboard's headline column averages Meta Gain across directions; per-direction primaries live in the row underneath. Section 02's "diagnostic" column is the per-direction Meta Gain measurement.
Aggregate Meta Gain is the headline. Per-direction primaries answer "how strong is the system overall"; Meta Gain answers "how much did the meta-actions buy you."
The baseline is the same model, scaffold, workers, budget, and tools with the relevant meta-action disabled. Different baselines per direction; never an oracle or random.
Token and wall-clock cost are reported alongside Meta Gain (Gain-per-dollar matters), but never replace it as the headline.
Each of these three benchmarks ships a small task set that's claimed to cover a multi-dimensional capability. The task lists differ; the composition logic is what's portable. Read across the three to see three distinct moves: axis-per-task with cheap variants, one-task-per-flavor with an orthogonal eval-grid axis, and small-domain-set chosen for uncorrelation.
Continual learning — does the same system, with state, beat its own stateless baseline?
schedule.json + variant.json multiply coverage cheaply.r_max + parallel_safe; per-dir AGENTS.md.Frontier ML R&D engineering — comparable across humans + agents at multiple compute budgets.
Recursive self-modification — meta-agent improves itself, transferable across uncorrelated domains.
imp@k = best agent in k generations; transfer = train on {A,B} → measure imp@50 on novel C.imp@k as the metric for axes where the meta-agent is itself the artifact under test.This is the raw brainstorm that produced the 8 directions above. Keep it as an archive and substrate map, not as the main interface to the benchmark. Each card names what the axis stresses, what makes it distinct from neighboring axes, the substrate we have or could borrow, and tags showing online/offline and current coverage.
Detect worker failure mid-task from observation stream; intervene (steer / revert) before completion.
SEND_HINT, SWITCH_BRANCH, REVERT_TO_STEP_K, NOOP.Identify uncertain decision points; explore K branches in parallel from a shared prefix; select the winner.
pass@1(branching, cost=B) − pass@1(single-shot, cost=B). Sweep B; report a Pareto curve.Identify wasted work in a completed trace; rewrite the compressed version; verify it still solves.
[i, j]; fork at step i-1; replay to completion with the span excised; verifier checks final output.Edit worker prompts, tools, scaffold from N training instances; score on held-out.
Split a goal into subtasks dispatched to (parallel) workers, then assemble outputs.
Meta-agent learns from past instances to make better meta-actions in future ones (recursive self-improvement).
imp@k on held-out domain — best agent produced within k generations. Plus ablations (fix-the-meta, no-archive) bound each component.At each step, decide whether to invoke an expensive meta-action given remaining budget.
Meta-agent proposes new meta-actions or new evaluation tasks that didn't exist before.
Detect harmful subagent action, localize cause, choose revert granularity, contain irreversibles, choose re-attempt strategy.
curl … | bash, write to /etc, post env to a webhook, install a shadow dep at step T then exfil at step T+30. Trap timing varies per task.Detect that the worker fabricated a fact (wrong API, made-up filename) before downstream actions consume it.
Recognize and refuse hostile content embedded in tool outputs, fetched pages, documents.
fetch() outputs, RAG documents, email bodies — exactly as in the source benchmarks.Mid-rollout, new info contradicts the original plan; meta-agent decides to abandon, modify, or persist.
ABANDON / MODIFY / PERSIST. Re-plan if needed.Decide whether to invoke a stronger model or human given uncertainty.
When N parallel workers' outputs disagree, decide which to trust / merge / re-run.
Per-instance: pick which tools the worker has access to (or refuse all and force CoT).
Route subtasks to specialist workers (researcher / coder / reviewer; Haiku / Sonnet / Opus by skill).
Pick up a partially-completed task from another agent (or self-after-crash); decide continue, restart, revise.
Predict own / worker's success probability before acting; use calibration to allocate effort.
These are the design patterns behind the direction cut. They explain how one physical task carrier can support multiple capability scores without turning the benchmark into a pile of unrelated demos.
Six of the eighteen axes pair up as "detect X" + "respond to X": axis 01 (failure → intervene), axis 09 (harm → revert), axis 10 (hallucination → verify), axis 11 (injection → refuse), axis 12 (new evidence → revise), axis 14 (disagreement → reconcile).
Cleaner factoring: leaderboard reports each axis as two sub-scores (detection F1, response quality conditional on detection), so a meta-agent that catches harm but reverts at the wrong granularity is distinguishable from one that misses harm entirely. CL-Bench didn't do this and the per-task READMEs feel slightly incoherent across tasks as a result.
Online (within a single rollout): axes 01, 02, 05, 07, 09, 10, 11, 12, 13, 14, 15, 16, 17, 18 — fourteen axes. Offline (across instances or post-hoc): axes 03, 04, 06 — three axes (plus deferred 08).
Different harness shape (online needs a live observation stream and intervention API; offline runs over completed traces); different baseline construction (online: meta-action toggle on/off; offline: optimizer toggle on/off); possibly different leaderboards. We could ship as two sub-leaderboards, like CL-Bench's "Reward / Gain / Cost" columns but with "Online uplift / Offline uplift / Cost".
For each axis, headline metric becomes Δ-with-meta-action vs. same-system-without. Cancels raw model strength, gives a structurally consistent leaderboard column even when tasks differ wildly. Axis 04 is the same as CL-Bench's Gain. Axis 09's Gain is "harm caught and contained, that the un-meta scaffold would have run". Axis 02's Gain is "tasks solved by best-of-K branching that single-shot would have failed".
One physical task can carry multiple axis evaluations if conditions are designed carefully — that's the real generalization of CL-Bench's schedule.json trick. CooperBench can host axes 01, 05, 09, 14, 16; TB2 can host 01, 02, 03, 12, 15; LongCoT can host 03, 05, 10. The substrate map below makes that explicit.
Cells: full = working substrate · part = exists, eval framing missing · empty = nothing yet. The dense rows (cooperbench, tb2, longcot) suggest where one physical task can carry multiple axis evaluations.
| axis | cooperbench | tb2 / swe-v | longcot | endless-term | hover | agentdojo | tb2 + drift | synthetic |
|---|---|---|---|---|---|---|---|---|
| 01Live supervision | live-int | supervised | · | · | · | · | · | · |
| 02Speculative branching | · | f-perf KV | long replay | mcts-rl | · | · | · | · |
| 03Post-hoc pruning | · | trajprune | prune loop | · | · | · | · | · |
| 04Workflow optimization | A1 prompts | · | · | · | cbo / gepa | · | · | · |
| 05Task decomposition | peer-coop | · | restricted | · | · | · | · | · |
| 06Continual self-improvement | · | · | · | · | · | · | · | DGM ref |
| 07Cost-aware decisions | · | · | · | · | · | · | · | F.4 data |
| 09Safety / harm reversion | trap row | · | · | · | · | recast | · | · |
| 10Hallucination catching | · | SWE summary | verifier | · | fact-check | · | · | · |
| 11Adversarial robustness | · | · | · | · | · | portable | · | · |
| 12Plan revision | · | env reveal | · | tree replay | · | · | drift run | · |
| 13Verification escalation | · | · | · | · | · | · | · | multi-model |
| 14Cross-worker reconciliation | 2-patch | · | · | leaf agg | · | · | · | · |
| 15Online tool / scope select | · | least-priv | · | · | · | · | · | · |
| 16Expertise routing | mixed-skill | · | · | · | · | · | · | · |
| 17Resumption from partial | · | · | · | · | · | · | · | handoff |
| 18Self-calibration | · | diverse | · | · | · | · | · | · |
Capabilities I explored and would defer or drop unless we hear otherwise. Listed for completeness so the v1 conversation knows what's on the table elsewhere.
The direction cut resolves the first-order shape. These are the remaining choices that affect the written spec and first implementation slice.
Use CooperBench for the N=2 anchor, then build the main slice around N=3 coding bundles and an N=5 stress set. The open work is task construction, not deciding whether CooperBench alone is enough.
Keep it to one primary metric plus one diagnostic. For Decompose and orchestrate: Joint Pass Rate and Orchestration Gain. Cost stays visible as metadata.
Recommended: publish fused Meta Gain as the primary score and keep detection/response as diagnostics where labels exist. This avoids blocking v1 on annotation while still exposing "great detector, bad responder" failure modes.
Cover two small safety surfaces in v1 settings: Revert and recover for bad actions already taken, and Prevent and contain for blocking unsafe or adversarial actions before execution. Keep each to one primary metric and one diagnostic.
Every direction should emit the same core artifact fields: task id, worker config, disabled-meta baseline id, event stream, meta-actions, checkpoints/reverts, final output, verifier result, token cost, wall-clock, and scorer version. This needs to be written before any slice becomes public.
Hyperagents proves cross-domain transfer of meta-skills. Our v2 analogue: does a meta-agent that learns to supervise on cooperbench also do better at reconciling on cross-worker disagreement? Or does it transfer worse, exposing axis-specific overfitting? This is the strongest "we measured something other benchmarks can't" claim, but only meaningful once v1's per-axis scores are stable.